Elucidating the Theoretical Underpinnings of Surrogate Gradient Learning in Spiking Neural Networks
Gygax, Julia & Zenke, Friedemann.
Neural Computation, 2025
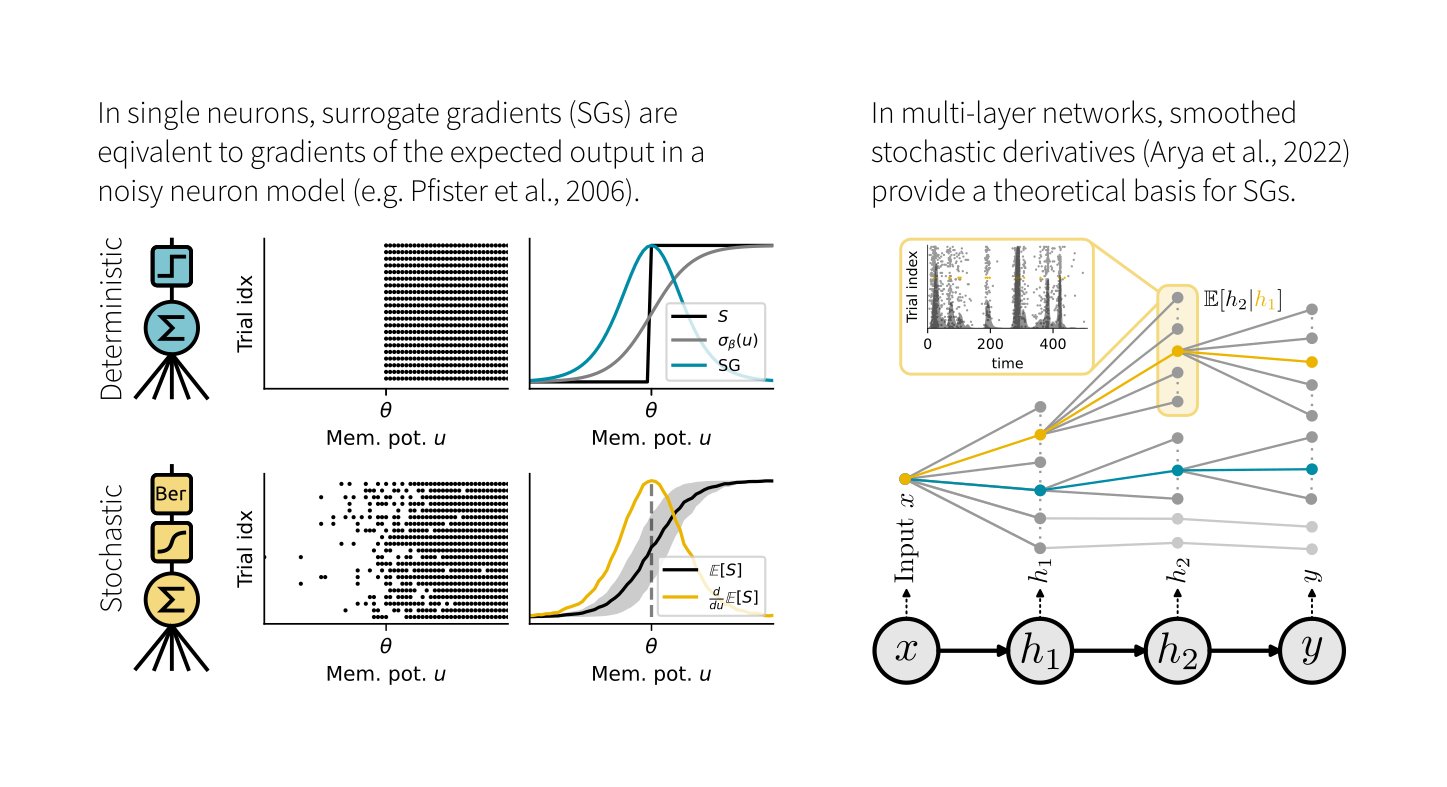
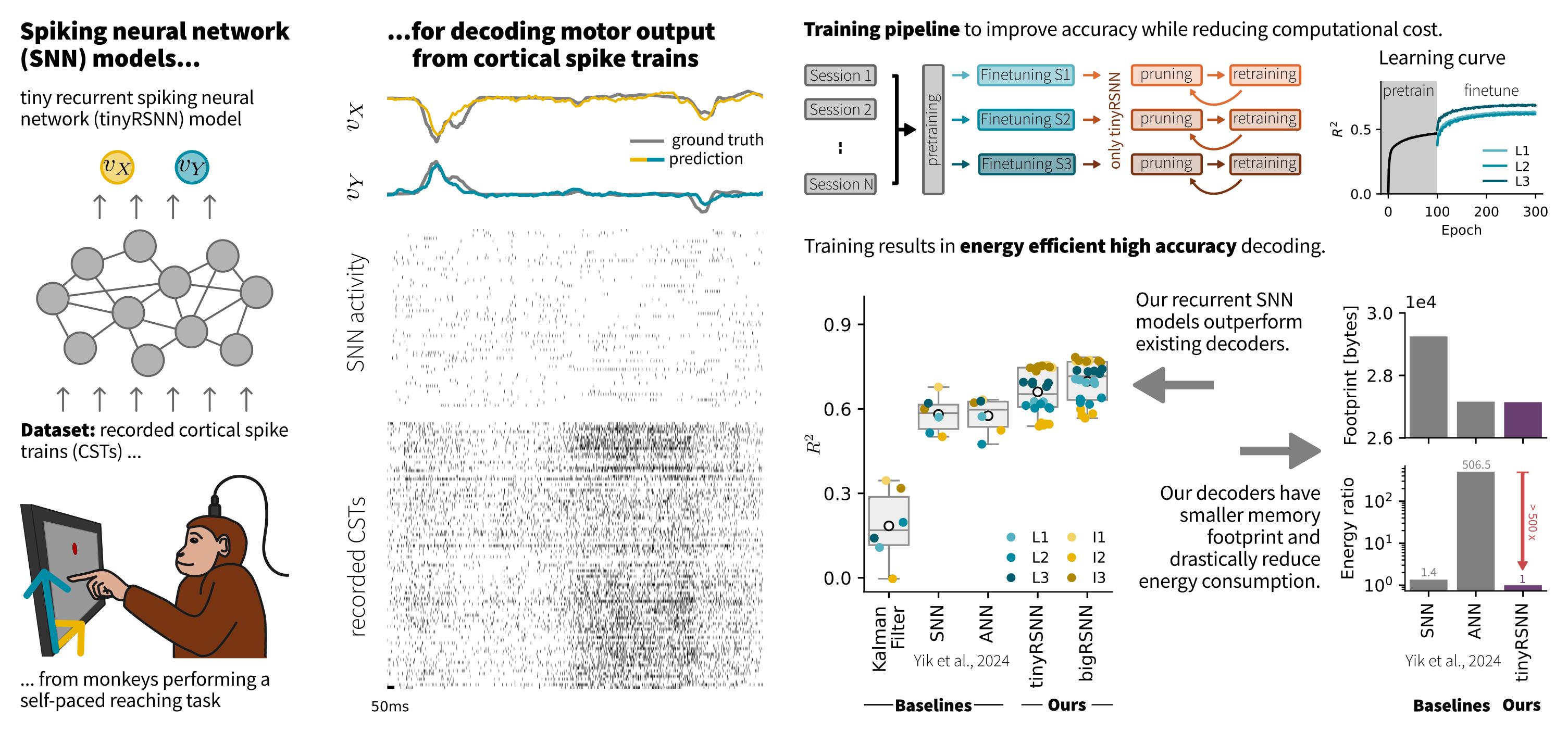
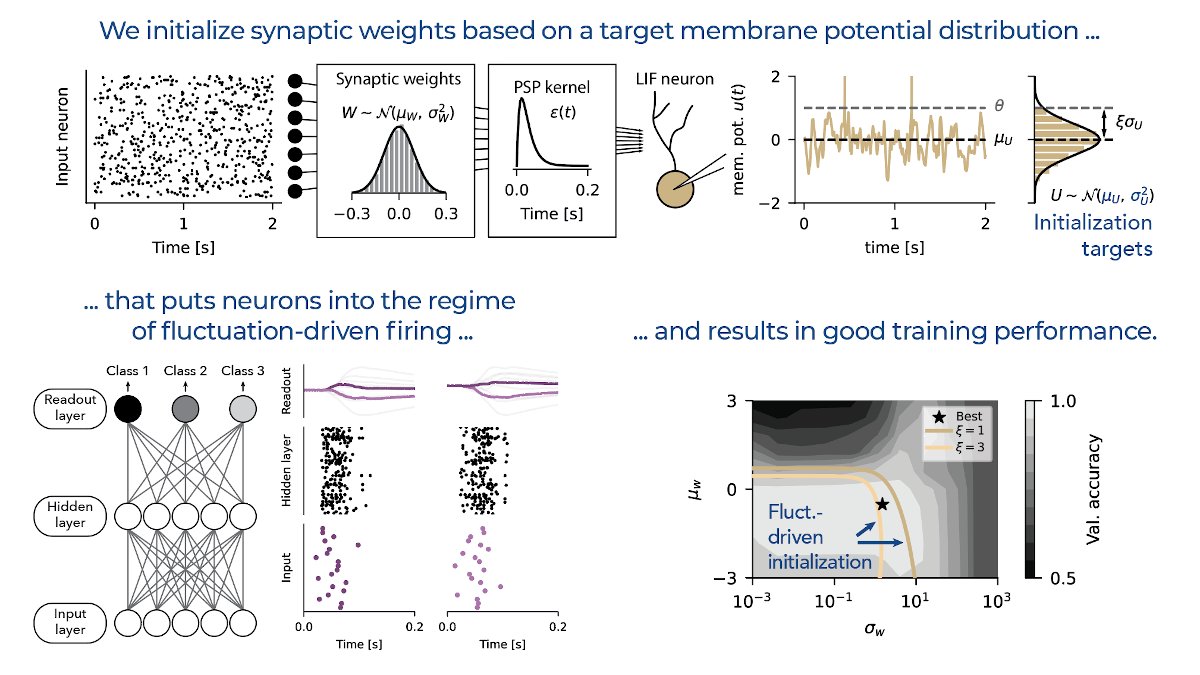
Training spiking neural networks (SNNs) to approximate complex functions is essential for studying information processing in the brain and neuromorphic computing. Yet, the binary nature of spikes constitutes a challenge for direct gradient-based training. To sidestep this problem, surrogate gradients (SGs) have proven empirically successful, but their theoretical foundation remains elusive. Here, we investigate the relation of SGs to two theoretically well-founded approaches. On the one hand, we consider smoothed probabilistic models, which, due to lack of support for automatic differentiation, are impractical for training deep SNNs, yet provide gradients equivalent to SGs in single neurons. On the other hand, we examine stochastic automatic differentiation, which is compatible with discrete randomness but has never been applied to SNN training. We find that the latter provides the missing theoretical basis for SGs in stochastic SNNs. We further show that SGs in deterministic networks correspond to a particular asymptotic case and numerically confirm the effectiveness of SGs in stochastic multi-layer SNNs. Finally, we illustrate that SGs are not conservative fields and, thus, not gradients of a surrogate loss. Our work provides the missing theoretical foundation for SGs and an analytically well-founded solution for end-to-end training of stochastic SNNs.